Die Parallelisierung von größeren DELETE- und UPDATE-Aktionen bietet diverse Vorteile:
- Die Performance wird durch den parallelen Zugriff erhöht.
- Es wird weniger Platz in den Undo-Segmenten verbraucht, da die Transaktion auf mehrere kleinere Einheiten verteilt wird.
- Die Tabellen sind nicht so lange offline, da die Sperren schneller aufgehoben werden können.
Wenn man selber prozedurale Lösungen zum parallelen Löschen oder Aktualisieren großer Datensatzmengen erstellen will, wird das allerdings schnell mühsam, weil man erst einmal sicherstellen muss, dass die Pakete so aufgeteilt werden, dass sich die einzelnen Transaktionen nicht gegenseitig behindern.
Ab der Oracle Version 11 Release 2 gibt es eine Oracle-eigene Lösung für die Parallelisierung von DML-Aktionen über den Scheduler, die den Anwendern sehr viel Arbeit abnehmen kann, das Package DBMS_PARALLEL_EXECUTE.
In diesem Fall werden die Tabellen über einen DBMS_SCHEDULER-Prozess automatisch in Teilbereiche, sog. Chunks, unterteilt (die aber nichts mit den Chunks bei der Speicherung von LOBs zu tun haben). Auf diese Abschnitte werden die DML-Befehle parallel abgesetzt. Ein COMMIT erfolgt nach jeder Fertigstellung des DML-Befehls auf dem jeweiligen Tabellenbereich. Dadurch werden die Undo-Segmente weniger stark belastet.
Um das Fehlerlogging und automatische Wiederholungen im Fehlerfall kümmert sich ebenfalls der Scheduler.
Die einzige Voraussetzung für die Nutzung ist das CREATE JOB-Recht. Das Package an sich ist an Public gegrantet. Im Gegensatz zu den meisten anderen Optionen, die mit Parallelisierung zu tun haben, ist die Nutzung des Packages nicht auf die Enterprise Edition beschränkt!!
Das Package besteht aus folgenden Prozeduren, die alle einen Commit beinhalten.
- CREATE_TASK erstellt einen Auftrag für die parallele Abarbeitung.
- Über CREATE_CHUNKS_BY_ROWID kann man die Teilbereiche der Tabelle über die ROWID definieren. Diese Unterteilung ist die unkomplizierteste Methode. Die Abschnitte überlappen sich garantiert nicht, insofern hat man auch keine Probleme mit Sperren und die Tabelle muss für das Chunking nicht extra abgefragt werden, da die Informationen über die ROWIDs bequem aus dem Data Dictionary bezogen werden können.
- Wenn man die Aufteilung der Tabelle über ein SQL-Statement bestimmen will, benutzt man CREATE_CHUNKS_BY_SQL.
- Auch eine Stückelung anhand der Werte einer numerischen Spalte ist möglich, die entsprechende Prozedur heißt CREATE_CHUNKS_BY_NUMBER_COL.
- Nach dem Erstellen der Chunks startet man die Abarbeitung über die Prozedur RUN_TASK.
- TASK_STATUS liefert Informationen über den Status.
- STOP_TASK würgt den Auftrag ab.
- RESUME_TASK startet die Wiederaufnahme.
- DROP_TASK löscht den Task.
Die Funktion TASK_STATUS kann zum Monitoren und zur Fehlerbehandlung genutzt werden.
BEISPIEL: PARALLELER UPDATE, EINTEILUNG ÜBER DIE ROWID
Probieren's wir mal aus. Für den ersten Test nehmen wir Tom Kytes bewährte Tabelle Initiates file downloadbig_tab mit 2 Millionen Datensätzen. Weil wir später die Session_ids bei der parallelen Ausführung ermitteln wollen, benennen wir die data_object_id-Spalte in session_id um.
Zunächst braucht Scott das Create Job-Recht:
conn / as sysdba
GRANT CREATE JOB TO scott;
conn scott/tiger
@ d:/create_bigtab.sql
ALTER TABLE big_tab RENAME COLUMN data_object_id TO session_id;
Jetzt kann Scott einen Task erstellen. Der Taskname ist einfach ein VARCHAR2-Parameter. Er muss nicht den Regeln für Oracle-Bezeichner entsprechen:
BEGIN
DBMS_PARALLEL_EXECUTE.create_task (task_name => 'update big_tab, chunks by rowid');
END;
Ob die Erstellung geklappt hat, kann man über die View USER_PARALLEL_EXECUTE_TASKS herausfinden:
col task_name for a50
SELECT task_name, status FROM user_parallel_execute_tasks;
=>
TASK_NAME STATUS
------------------------------------- ----------
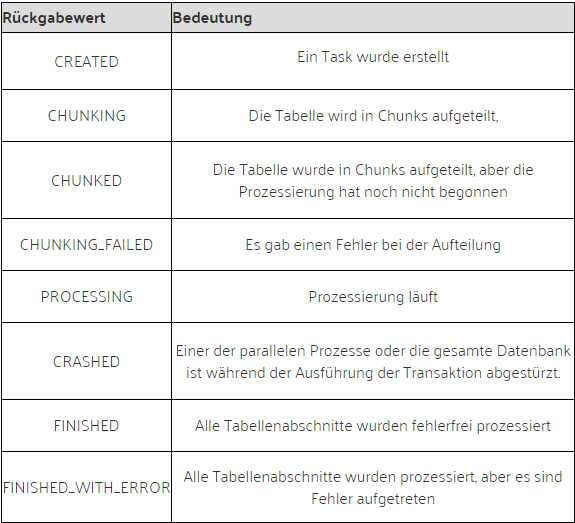
update big_tab, chunks by rowid CREATED
Falls einem grad kein passender Name einfällt, kann man die Funktion GENERATE_TASK_NAME verwenden, die eine interne Sequenz hochzählt:
SELECT DBMS_PARALLEL_EXECUTE.generate_task_name FROM dual;
=> TASK$_1
Der nächste Schritt ist die Unterteilung der Tabelle. Wenn der Parameter by_row auf TRUE gesetzt wird, bezieht sich die chunk_size auf die Anzahl der Zeilen, wenn er auf FALSE steht, auf die Anzahl der Blöcke.
Optimale Werte für die chunk_size muss man selber ermitteln. Je kleiner die chunk_size, desto schneller sind die Tabellenabschnitte wieder frei von Sperren:
BEGIN
DBMS_PARALLEL_EXECUTE.create_chunks_by_rowid(
task_name => 'update big_tab, chunks by rowid',
table_owner => 'SCOTT',
table_name => 'BIG_TAB',
by_row => TRUE,
chunk_size => 10000);
END;
/
SELECT task_name, status FROM user_parallel_execute_tasks;
TASK_NAME STATUS
------------------------------------- -------------
update big_tab, chunks by rowid CHUNKED
Genauere Informationen über die einzelnen Abschnitte liefert die View USER_PARALLEL_EXECUTE_CHUNKS:
SELECT chunk_id, status, start_rowid, end_rowid
FROM user_parallel_execute_chunks
WHERE task_name = 'update big_tab, chunks by rowid'
ORDER BY chunk_id;
=>
CHUNK_ID STATUS START_ROWID END_ROWID
-------- -------------------- ------------------ ------------------
2 UNASSIGNED AAAVbmAAEAAAGegAAA AAAVbmAAEAAAGenCcP
3 UNASSIGNED AAAVbmAAEAAAGeoAAA AAAVbmAAEAAAGevCcP
4 UNASSIGNED AAAVbmAAEAAAGewAAA AAAVbmAAEAAAGe3CcP
5 UNASSIGNED AAAVbmAAEAAAGe4AAA AAAVbmAAEAAAGe/CcP
6 UNASSIGNED AAAVbmAAEAAAGfAAAA AAAVbmAAEAAAGfHCcP
....
331 Zeilen ausgewählt.
Jetzt folgt die eigentliche Ausführung:
In diesem Beispiel werden 10 parallele Prozesse (Scheduler-Jobs) gestartet, die sich jeweils einen der nicht zugeordneten (unassigned) Abschnitte vornehmen, die über den Parameter sql_stmt vorgegebene DML-Anweisung durchführen, festschreiben und zum nächsten freien Chunk übergehen. Wenn man z. B. nur 4 Prozessoren hat, laufen die Jobs natürlich teilweise seriell.
Der Quotation-Operator (q'[...]') erlaubt die Schreibweise ohne Maskierung der inneren Hochkommata:
DECLARE
l_stmt VARCHAR2(32767);
BEGIN
l_stmt := q'[UPDATE big_tab
SET data_object_id = sys_context('userenv', 'sessionid'),
object_type = object_type||'*',
created = sysdate
WHERE rowid BETWEEN :start_id AND :end_id]';
DBMS_PARALLEL_EXECUTE.run_task(
task_name => 'update big_tab, chunks by rowid',
sql_stmt => l_stmt,
language_flag => DBMS_SQL.NATIVE,
parallel_level => 10);
END;
/
Abgelaufen: 00:00:48.98
Die Bindvariablen :start_id and :end_id beziehen sich auf die erste bzw. letzte Rowid jedes Chunks.
Der Eintrag der Session_id über die Sys_constext-Funktion ermöglicht auch nachträglich, festzustellen, welcher Anteil der Zeilen in welcher der parallelen Sessions erledigt wurde:
SELECT data_object_id session_id, COUNT(*)
FROM big_tab
GROUP BY data_object_id
ORDER BY data_object_id;
=>
SESSION_ID COUNT(*)
---------- ----------
7491384 279693
7491385 283494
7491386 273875
7491387 260867
7491388 141022
7491389 143615
7491390 153054
7491391 154875
7491392 161342
7491393 148163
STATUS INFORMATIONEN UND DIAGNOSE-MÖGLICHKEITEN
Ob alles glatt gegangen ist, erfährt man über die Data Dictionary-Views:
SELECT status,
job_prefix, -- für die parallelen Scheduler-Jobs
chunk_type,
-- sql_stmt,
parallel_level
FROM user_parallel_execute_tasks
WHERE TASK_NAME = 'update big_tab, chunks by rowid';
=>
STATUS JOB_PREFIX CHUNK_TYPE PARALLEL_LEVEL
---------- -------------- ------------ --------------
FINISHED TASK$_241 ROWID_RANGE 10
SELECT status, COUNT(*)
FROM user_parallel_execute_chunks
GROUP BY status;
STATUS COUNT(*)
-------------------- ----------
PROCESSED 331
Aufschlussreich ist auch die Scheduler-DD-View user_scheduler_job_run_details. Hierfür muss man nur das Job-Präfix aus der View user_parallel_execute_tasks für die Job-Namen einsetzen:
SELECT job_name,
status,
error#,
SUBSTR(run_duration, INSTR(run_duration,':')+1) "Dauer [Sek]",
REGEXP_SUBSTR(actual_start_date, '[^ ]+') uhrzeit
FROM user_scheduler_job_run_details
WHERE job_name LIKE (SELECT job_prefix || '%'
FROM user_parallel_execute_tasks
WHERE task_name = 'update big_tab, chunks by rowid');
=>
JOB_NAME STATUS ERROR# Dauer [Sek] UHRZEIT
-------------- ---------- ---------- -------------- ----------------
TASK$_241_6 SUCCEEDED 0 00:40 17:46:52,578000
TASK$_241_9 SUCCEEDED 0 00:40 17:46:52,781000
TASK$_241_1 SUCCEEDED 0 00:46 17:46:46,781000
TASK$_241_10 SUCCEEDED 0 00:40 17:46:52,843000
TASK$_241_2 SUCCEEDED 0 00:46 17:46:46,890000
TASK$_241_3 SUCCEEDED 0 00:46 17:46:46,953000
TASK$_241_4 SUCCEEDED 0 00:46 17:46:47,109000
TASK$_241_7 SUCCEEDED 0 00:40 17:46:52,656000
TASK$_241_8 SUCCEEDED 0 00:40 17:46:52,718000
TASK$_241_5 SUCCEEDED 0 00:40 17:46:52,578000
Nach der erfolgreichen Ausführung kann man den Task löschen:
BEGIN
DBMS_PARALLEL_EXECUTE.drop_task('test_task');
END;
FEHLERLOGGING
Was macht man, wenn bei der Prozessierung Fehler auftreten? Wir bauen ein paar Fallen in die Tabelle ein. Die Spalte object_type ist vom Datentyp VARCHAR2(19). Während des Updates wird der Wert mit einem Sternchen konkateniert, also muss ich nur ein paar Einträge verlängern, so dass es während der DML-Aktion kracht:
UPDATE big_tab SET object_type = RPAD(object_type, 19, '+') WHERE MOD(id, 43) = 0;
=> 46511 Zeilen wurden aktualisiert.
In der PL/SQL Packages and Types Reference findet sich ein Beispiel für die Ausführung der Prozedur incl. Fehlerbehandlung. Statt RUN_TASK wird hier die Prozedur GET_ROWID_CHUNK eingesetzt:
DECLARE
v_stmt VARCHAR2(32767);
v_chunk_id NUMBER;
v_start_rowid ROWID;
v_end_rowid ROWID;
v_rows_left BOOLEAN;
v_errcnt NUMBER := 0;
BEGIN
BEGIN
DBMS_PARALLEL_EXECUTE.drop_task('update big_tab, chunks by rowid');
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('Task bereits vorhanden, wird gelöscht');
END;
v_stmt := q'[UPDATE big_tab
SET session_id = sys_context('userenv', 'sessionid'),
object_type = object_type||'*',
created = sysdate
WHERE rowid BETWEEN :start_id AND :end_id]';
-- Task erstellen
DBMS_PARALLEL_EXECUTE.create_task (
task_name => 'update big_tab, chunks by rowid');
-- Aufteilung in Chunks
DBMS_PARALLEL_EXECUTE.create_chunks_by_rowid(
task_name => 'update big_tab, chunks by rowid',
table_owner => 'SCOTT',
table_name => 'BIG_TAB',
by_row => TRUE,
chunk_size => 10000);
LOOP
-- Solange Zeilen zu prozessieren sind
-- liefert GET_ROWID_CHUNK den nächsten noch nicht zugewiesenen Chunk
DBMS_PARALLEL_EXECUTE.get_rowid_chunk(
task_name => 'update big_tab, chunks by rowid',
chunk_id => v_chunk_id,
start_rowid => v_start_rowid,
end_rowid => v_end_rowid,
any_rows => v_rows_left);
EXIT WHEN v_rows_left = FALSE;
-- Im Unterblock wird die eigentliche DML-Aktion durchgeführt
BEGIN
EXECUTE IMMEDIATE v_stmt USING v_start_rowid, v_end_rowid;
-- Wenn alles glatt geht, wird der Chunk status auf 'processed' gesetzt.
DBMS_PARALLEL_EXECUTE.set_chunk_status(